- 高可用性:数据库服务器可以一起工作, 这样如果主要的服务器失效则允许一个第二服务器快速接手它的任务
- 负载均衡: 允许多个计算机提供相同的数据
本文使用的主要技术有:
- CentOS 7 x86_64
- PostgreSQL 9.6.5
系统安装、配置
CentOS 7 安装
1 | [hldev@centos7-001 ~]$ sudo yum -y install https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm epel-release vim |
CentOS 系统配置
Selinux配置
编辑 /etc/sysconfig/selinux,设置 SELINUX 为 disabled:
1 | # This file controls the state of SELinux on the system. |
其它配置
TODO
修改完后请重启系统,以确保所有设置生效。
PostgreSQL 安装
1 | [hldev@centos7-001 ~]$ sudo yum -y install postgresql96-server postgresql96-contrib |
初始化PostgreSQL数据库
1 | [hldev@centos7-001 ~]$ sudo /usr/pgsql-9.6/bin/postgresql96-setup initdb |
启动PostgreSQL
1 | [hldev@centos7-001 ~]$ sudo systemctl start postgresql-9.6 |
使用 sudo systemctl status postgresql-9.6 来检测PG运行状态。看到如下输出,则代表数据库安装成功。
1 | ● postgresql-9.6.service - PostgreSQL 9.6 database server |
PostgreSQL单机配置
配置PostgreSQL
登录 postgres 操作系统账号:
1 | [hldev@centos7-001 ~]$ sudo su - postgres |
编辑 /var/lib/pgsql/9.6/data/pg_hba.conf 文件,将 host all all 127.0.0.1/32 ident 修改为允许所有网络登录,并使用md5方式进行认证:
1 | host all all 0.0.0.0/0 md5 |
编辑 /var/lib/pgsql/9.6/data/postgresql.conf 文件,找到并设置如下选项:
1 | listen_addresses = '*' |
通过以上配置,我们设置了PostgreSQL允许任何IPv4地址都可以使用密码认证的方式登录数据库,并设置密码使用加密传输/存储,同时还修改了最大连接数限制为1000。
设置postgres(数据库超级管理员)密码
首先使用 psql 命令登录PostgreSQL数据库
1 |
|
使用 \password 命令设置当前用户密码
1 | postgres=# \password |
注意:此处需要在 postgres 操作系统账号下操作
打开防火墙端口
要使本机以外可远程连接数据库,还需要打开操作系统防火墙的对应端口。PostgreSQL在安装时提供了 firewalld 的服务配置文件,我们可以通过服务的方式来打开防火墙:
1 | sudo firewall-cmd --add-service=postgresql --permanent |
以上修改后需要重启PostgreSQL数据库
1 | exit # 退出postgres账号 |
远程连接PostgreSQL数据库
在远程主机上使用以下命令连接已安装好的PostgreSQL数据库,centos7-001 为已安装数据库服务器主机IP地址对应主机名(通过在 /etc/hosts 中设置 192.168.124.146 centos7-001 来映射)。
1 | [hldev@centos7-001 ~]$ psql -h centos7-001 -U postgres |
登录成功后,我们看到如下提示则代表 PostgreSQL 的单机安装成功完成:
1 | 用户 postgres 的口令: |
PostgreSQL 集群设置
这里列出官方对各种高可用、负载均衡和复制特性实现方式的比较:
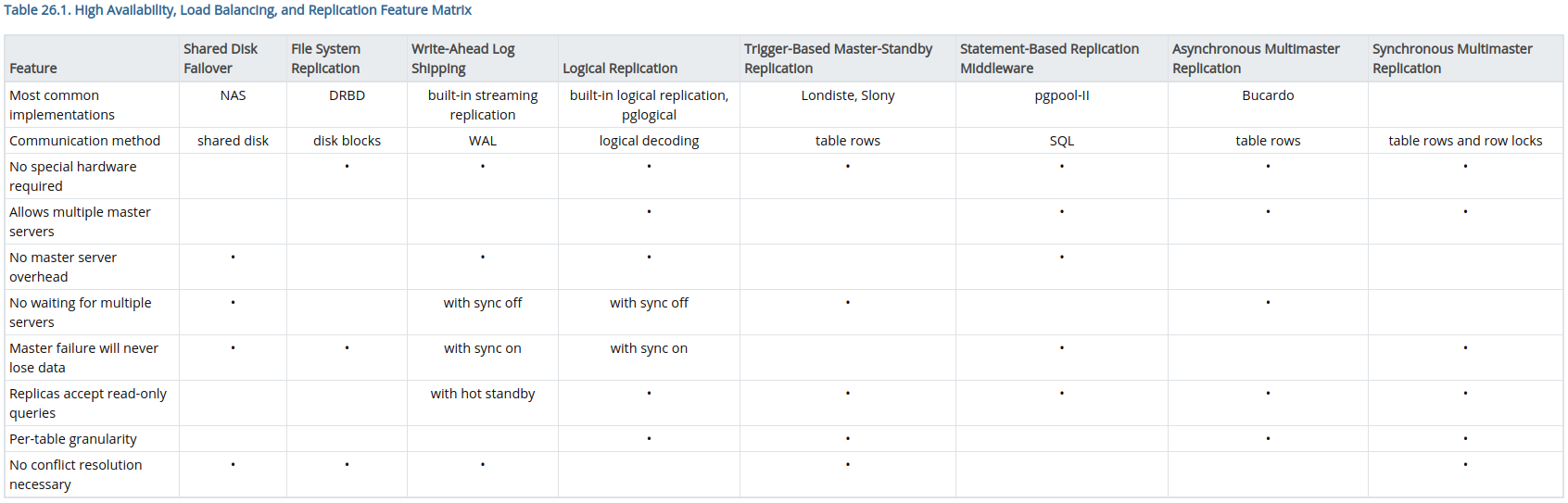
本文将基于PostgreSQL官方提供的基于流式的WAL数据复制功能搭建一个 主/热备 数据库集群。
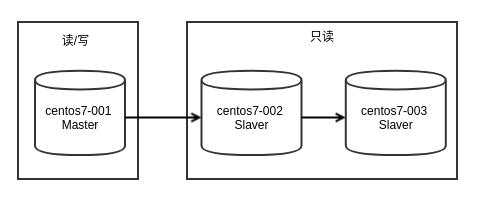
根据 PostgreSQL单机配置,安装3台服务器。IP地址设置分别如下,并加入 /etc/hosts 中:
1 | 192.168.124.161 centos7-001 |
三台服务器的角色分别如下:
- centos7-001: 主服务器
- centos7-002: 从服务器
- centos7-003: 级联从服务器
主节点(centos7-001)
1.. 创建一个传用于复制的账号:
1 | CREATE ROLE pgrepuser REPLICATION LOGIN PASSWORD 'pgreppass'; |
2.. 在 postgresql.conf 设置以下配置项:
1 | listen_addresses = '*' |
3.. 在 pg_hba.conf 文件中为 pgrepuser 设置权限规则。允许 pgrepuser 从IP地址范围为 192.168.124.1 到
192.168.124.254 连接到主服务器,并使用基于MD5的加密密码。
1 | host replication pgrepuser 0.0.0.0/0 md5 |
主服务器配置好后需要重启数据库:
1 | [hldev@centos7-001 ~]$ sudo systemctl restart postgresql-9.6 |
若在生产环境中没有条件进行数据库重启,也可以使用 pg_ctl reload 指令重新加载配置:
1 | -bash-4.2$ /usr/pgsql-9.6/bin/pg_ctl reload -D $PGDATA |
从节点
1.. 首先停止从机上的PostgreSQL服务。
1 | sudo systemctl stop postgresql-9.6 |
2.. 使用 pg_basebackup 生成备库
首先清空 $PGDATA 目录。
1 | -bash-4.2$ cd /var/lib/pgsql/9.6/data |
使用 pg_basebackup 命令生成备库:
1 | -bash-4.2$ /usr/pgsql-9.6/bin/pg_basebackup -D $PGDATA -Fp -Xs -v -P -h centos7-001 -U pgrepuser |
我们看到以下的操作输出,代表生成备库成功。
1 | pg_basebackup: initiating base backup, waiting for checkpoint to complete |
3.. 将下面的配置设置添加到 postgresql.conf 文件中。
1 | hot_standby = on |
4.. 在 $PGDATA 目录创建 recovery.conf 文件,内容如下:
1 | standby_mode = 'on' |
5.. 如果发现从属服务器处理事务日志的速度较慢,跟不上主服务器产生日志的速度,为避免主服务器产生积压,你可以在从属服务器上指定一个路径用于缓存暂未处理的日志。请在 recovery.conf 中添加如下一个代码行,该代码行在不同操作系统下会有所不同。
1 | restore_command = 'cp %p ../archive/%f' |
6.. 启动从数据库
1 | [hldev@centos7-002 ~]$ sudo systemctl stop postgresql-9.6 |
启动复制进程的注意事项
一般情况下,我们建议先启动所有从属服务器再启动主服务器,如果顺序反过来,会导致主服务器已经开始修改数据并生成事务日志了,但从属服务器却还无法进行复制处理,这会导致主服务器的日志积压。如果在未启动主服务器的情况下先启动从属服务器,那么从属服务器日志中会报错,说无法连接到主服务器,但这没有关系,忽略即可。等所有从属服务器都启动完毕后,就可以启动主服务器了。
此时所有主从属服务器应该都是能访问的。主服务器的任何修改,包括安装一个扩展包或者是新建表这种对系统元数据的修改,都会被同步到从属服务器。从属服务器可对外提供查询服务。
如果希望某个从属服务器脱离当前的主从复制环境,即此后以一台独立的 PostgreSQL 服务器身份而存在,请直接在其 data 文件夹下创建一个名为 failover.now 的空文件。从属服务器会在处理完当前接收到的最后一条事务日志后停止接收新的日志,然后将 recovery.conf 改名为 recovery.done。此时从属服务器已与主服务器彻底解除了复制关系,此后这台PostgreSQL 服务器会作为一台独立的数据库服务器存在,其数据的初始状态就是它作为从属服务器时处理完最后一条事务日志后的状态。一旦从属服务器脱离了主从复制环境,就不可能再切换回主从复制状态了,要想切回去,必须按照前述步骤一切从零开始。
测试主/备服务
分别登录 centos7-001 和 centos7-002 两台数据库使用 \l 命令查看数据库列表:
PostgreSQL: centos7-001
1 | [hldev@centos7-001 ~]$ psql -h centos7-001 -U postgres |
PostgreSQL: centos7-002
1 | [hldev@centos7-002 ~]$ psql -h centos7-002 -U postgres |
我们在 centos7-001 上创建一个测试数据库:test
1 | postgres=# create database test template=template1; |
test 数据库创建成功后,我们可以在 centos7-002 从服务器上看到 test 数据库已经同步过来。
1 | postgres=# \l |
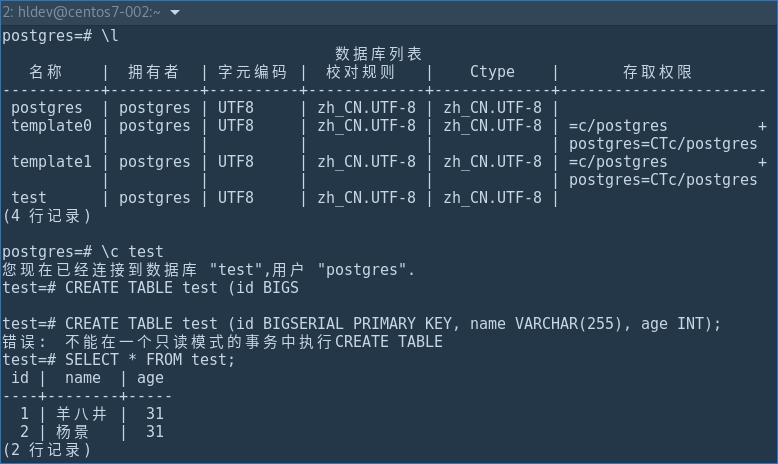
继续在从库上尝试 DDL 操作,可以发现从库已被正确的设置为只读模式:
1 | postgres=# \c test |
在主库上,我们可以正常的进行读写操作。同时主节点的 恢复(recovery) 模式为 false。
1 | test=# CREATE TABLE test (id BIGSERIAL PRIMARY KEY, name VARCHAR(255), age INT); |
让我们再切换到从库,执行 SELECT * FROM test 查询语句可以看到之前在主库上写入的两条记录已被成功复制过来。
级联从节点
1.. 按从节点的方式,停止数据库并使用 pg_basebackup 从 从节点 在线备份数据库到 $PGDATA 目录。
1 | [hldev@centos7-003 ~]$ sudo systemctl stop postgresql-9.6 |
2.. 配置 recovery.conf 运行参数。将 primary_conninfo 的 host 指定为从节点:centos7-002,同时添加恢复目标时间线 recovery_target_timeline 选项:
1 | standby_mode = 'on' |
并设置 recovery.conf 文件其它用户不能读取
1 | -bash-4.2$ chmod 0600 recovery.conf |
3.. 启动 级联从节点 ,并测试数据是否已同步。
1 | [hldev@centos7-003 ~]$ sudo systemctl start postgresql-9.6 |
可以看到,级联从节点已正常的从 从节点 将数据同步过来。同时,我们还可以看到当前数据库处于 恢复(recovery) 模式。
数据库复制状态
centos7-001
在主节点上,我们可以看到有一个复制节点连接上来,客户端地址(client_addr)为:192.168.124.162(centos7-002),使用流式复制(state),同步模式(sync_state)为异步复制。
1 | test=# \x |
centos7-002
而在从节点上看到也有一个复制节点连接上来,客户端地址(client_addr)为:192.168.124.163(centos7-003),使用流式复制(state),同步模式(sync_state)为异步复制。
1 | test=# \x |
主/备切换
1.. 关闭主节点数据库服务:
1 | [hldev@centos7-001 ~]$ sudo systemctl stop postgresql-9.6 |
2.. 将从节点(centos7-002)变为主节点
1 | -bash-4.2$ /usr/pgsql-9.6/bin/pg_ctl promote -D $PGDATA |
此时在节点 centos7-002 上,PostgreSQL数据库已经从备节点转换成了主节点。同时,recovery.conf 文件也变为了 recovery.done 文件,表示此节点不再做为从节点进行数据复制。
1 | test=# select pg_is_in_recovery(); |
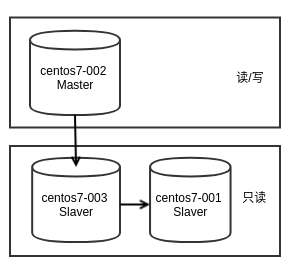
3.. 将原主节点(centos7-001)变为级联从节点(当前主节点已改为centos7-002)。
在 centos7-001 节点上编辑 postgresql.conf,并开启热备模式:
1 | hot_standby = on |
添加并编辑 recovery.conf 文件:
1 | standby_mode = 'on' |
(重)启动PostgreSQL数据库,节点 centos7-001 现在成为了一个 级联从节点 。
总结
PostgreSQL官方支持基于流式复制的WAL实现的主/热备高可用集群机制,同时我们还可以搭配 PgPool-II 在应用层实现