目录
- 微服务
- 配置
- Java Properties
- Typesafe Config
- 服务发现
- Akka Discovery
- Nacos(溶入Spring Cloud)
- 服务
- 序列化
- JSON
- Protobuf
- 服务协议
- RESTful(Akka HTTP)
- gRPC(HTTP 2)
- 序列化
- 集群
- 使用Akka Discovery + Akka gRPC构建微服务集群
- Akka Cluster可用于业务服务内部
- 反应式(Reactive)
- Akka Streams
- Alpakka
- 技术降级:Java里好用的工具可继续使用
- 监控
- 通过HTTP Header实现简单的调用链监控
- kamon:自动检测、监视和调试的分布式系统
- 实践
- 全栈 Akka
- 现实:与Spring Cloud一起
- Why not
- Play
- Lagom
- Akka
微服务
介绍微服务的文章和书箱已经很多了,这里就不再对此阐述过多。这里链接到 Martin Fowler的文章《Microservices》https://martinfowler.com/articles/microservices.html 。
本文要介绍的Akka微服务简化结构图如下:
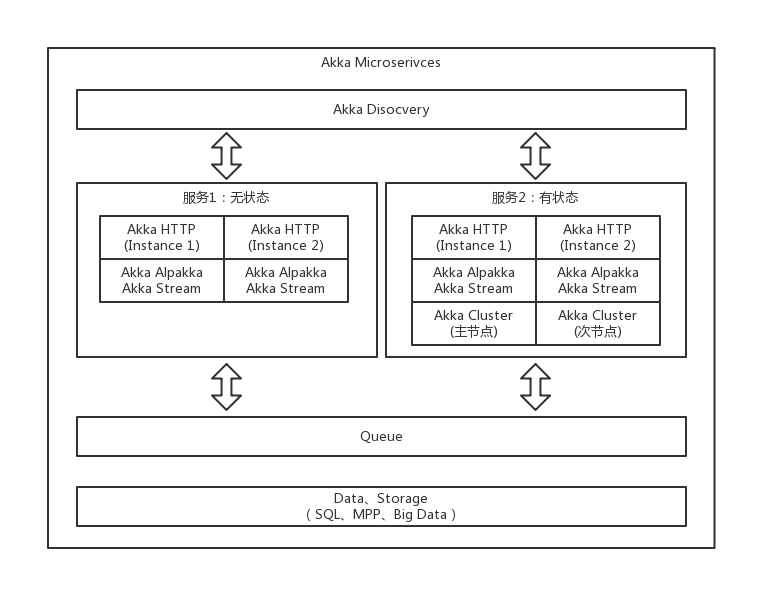
使用Akka来实现微服务,有如下函数式、异步、分布式、高并发、可扩展等特性和优势。
最重要的是,你将实现一个反应式的微服务。
配置
应用的运行都会从配置开始,在我们的实践中主要到两类配置方式:
- Java Properties
- Typesafe Config
传统应用,会从某个配置文件里读取应用需要的配置。而微服务架构下,会从一个统一的配置中心读取。配置中心有很多的选择,比如:Consul、Etcd、Spring Config、Nacos、Database等。同时,还希望可通过命令行参数设置配置项,而它的优先级应该比配置中心或配置文件更高。
Java Properties
Java Properties想必大家已经很熟悉了,可通过 .properties 文件或JVM命令行参数 -D 来指定。这里使用 -D 这样的命令行参数在启动时覆盖配置文件里的配置,而 .properties 配置文件的方式并不使用,因为你接下来会发现更好的配置文件。
Typesafe Config
Typesafe Config使用HOCON(Human-Optimized Config Object Notation)语言来编写配置,https://github.com/lightbend/config 能找到关于 Typesafe Config 更多的文档。
使-D命令行配置优先于Typesafe Config配置
1 | val cc = ConfigFactory.parseString("""{}""") // .load() |
- 获取初始配置;
defaultOverrides函数将JVM命令行参数(使用-D)解析到一个Config,同时将其与cc合并(cc与JVM命令行参数的配置合并,JVM命令行参数将覆盖cc里相同键的值);- 将合并了命令行参数的配置再与Typesafe Config默认配置合并,得到最终的配置。
服务发现
服务发现,作为微服务治理方面非常重要的一环,它是微服务的一个核心组件。通常大部分服务发现工具还带有健康检查等功能,比如:Nacos。
Akka Discovery
Akka Discovery是Akka团队专为Akka生态开发的服务发现接口(提供了统一的服务发现API,但并不实现具体的服务发现功能),支持:DNS、静态配置、Console、k8s等服务发现功能。Akka Discovery本身不带健康检查功能,由下层具体实现提供,同时,Akka Discovery设计为可扩展的,我们可以很容易的扩展它支持更多的服务发现框架。
Nacos
Nacos是阿里巴巴开源的一套使用Java语言编写的服务注册、服务发现框架,它提供了HTTP API、Java SDK等易用的集成方式,可单独使用,也集成到Spring Cloud里使用。Akka Discovery因其设计上强大的可扩展性,我们可以将其与Nacos集成。同时,对于已使用了Spring Cloud的团队来说,Akka服务也需要与已存在的Spring Cloud进行集成,而通过Akka Discovery -> Nacos -> Spring Cloud的形式集成两者是非常吸引人的。
1 | final class Lookup(val serviceName: String, val portName: Option[String], val protocol: Option[String]) |
NacosServiceDiscovery为集成Nacos的Akka Discovery实现,代码非常简单,我们只需要实现def lookup(lookup: Lookup, resolveTimeout: FiniteDuration): Future[ServiceDiscovery.Resolved]函数即可。
服务
微服务,重点在服务。包括:服务API、服务拆分、服务发现、服务治理等等。服务API最常用的就是基于HTTP RESTful来实现,同时也有很多采用RPC的方式,比如:gRPC、Thrift、Dubbo等。
序列化
服务API发布后,需要有一个序列化格式来说明API暴露的数据是怎样组成的,这就是数据的序列化。数据序列化通常是成对的,服务提供方编码(Marshal)数据,而服务消费方则解码(Unmarshal)数据。
JSON
JSON(JavaScript Object Notation,https://json.org/)是现在最常使用的服务间序列化方式,具有简单、简单、简单的特点。但使用JSON也有如下不足:
- 数据类型不够丰富;
- 没有类型静态约束;
- 文件传输,相比二进制数据还是偏大。
Protobuf
Protobuf是Google开发的一款二进制序列化工具,类似的还有Thrift、Flatbuf(速度比Protobuf更快,但二进制数据更大,相应网络传输占用会更多)、Dubbo(Dubbo可支持的语言现在还比较少,移动端支持也很弱)等,它相对JSON具有以下优点:
- 更丰富的数据类型;
- 静态类型约束;
- 有Shema描述文件,可自动生成数据类;
- 二进制传输,更省带宽。
服务协议
RESTful(Akka HTTP)
微服务发布的API,需要由某个协议来承载,最常用的就是基于HTTP协议的RESTful风格的形式了。Akka HTTP提供了丰富的HTTP特性,支持HTTP 1.0、1.1、2.0。
Akka HTTP提供了 Routing DSL(https://doc.akka.io/docs/akka-http/current/routing-dsl/index.html)高级API来定义服务接口。
1 | val route = |
你可以在《Scala Web开发》(https://www.yangbajing.me/scala-web-development/)学到更多有关Akka HTTP的知识。
gRPC(HTTP 2)
gRPC使用Protobuf进行数据序列化,基于HTTP 2提供RPC通信。具有快速、高效、易用、可扩展等特点。采用HTTP 2作为底层协议,可以更好的与已有的HTTP基础服务整合,简化了运维管理(不需要为了RPC单独开放网络端口,并对其进行管理)。gRPC支持请求/响应和Stream两种接口形式,可以实现服务端推送功能。
Akka提供了开箱即用的akka-grpc(https://doc.akka.io/docs/akka-grpc/current/),从编译、构建、发布……与Scala/Akka生态完美整合。**Why gRPC**(https://doc.akka.io/docs/akka-grpc/current/whygrpc.html)这篇文章详细的说明了为什么需要gRPC,特别是gRPC与REST、SOAP、Message Bus和Akka Remoting的区别,阐述的简明扼要。
1 | message HelloRequest { |
GreeterService描述了一个gRPC服务定义,接受HelloRequest并响应HelloReply。sbt-akka-grpc 插件提供了自动化构建gRPC的sbt插件,你可以如下使用:
1 | addSbtPlugin("com.lightbend.sbt" % "sbt-javaagent" % "0.1.5") |
更多sbt配置请查阅:https://doc.akka.io/docs/akka-grpc/current/buildtools/sbt.html
集群
多个服务之间相互通信,服务与服务既形成了集群。Akka基于actor模型,天然就是分布式的。Akka Cluster对于集群提供了原生支持。
- 这里建议服务与服务之间通过Akka Discovery来做服务发现,gRPC为通信协议;
- 有状态服务内多个实例之间使用Akka Cluster来形成一个服务的小集群(无状态服务的多个实例不需要集群),比如主/从架构。而对于多个实例之间需要共享数据的情况,可以使用Akka Distributed Data(https://doc.akka.io/docs/akka/2.6/typed/distributed-data.html)
使用Akka Discovery + Akka gRPC构建微服务集群
之前 服务发现 一章已介绍了 Akka Discovery,它是可扩展的,可快速的把你所使用的服务发现工具集成到Akka中。Akka gRPC提供了对Akka Discovery的支持,Akka gRPC客户端可通过Akka Discovery来发现服务。让我们来看一个服务发现配置的例子:
1 | akka.grpc.client { |
Endpoint:sample.HelloService是gRPC服务的全限定路径,每个Endpoint都需要有一个配置(注意:服务路径需要用双引号括起来,不然Typesafe Config会认为这个配置分割符)。在service-discovery配置内指定服务发现机制和服务名,而use-tls设置为false可以关闭https,对于内网服务之前的调用来说是可行的,它可以减少些流量。但若你的服务需要暴露到公网,强烈建议设置为true(默认值)。可以通过如下代码构造一个提供了服务发现支持的gRPC客户端:
1 | val settings = GrpcClientSettings.fromConfig(clientName = "sample.HelloService") |
Akka Cluster可用于业务服务内部
Akka Cluster Singleton
对于服务内多个实例之间,有时也需要集群化的需求。比如一个调用服务,为了保证高可用需要同时启多个实例,但(通常)只会有一个实例管理任务调度,其它实例只做为具体执行任务的Worker,或者不做任何事情,只是为了容错而在Primary节点挂掉是可自动选择其中一个提升为Primary以继续管理任务调度。Akka Cluster Singleton为此类Primary/Secondary模式提供了支持 (更多内容请参阅:https://doc.akka.io/docs/akka/2.6/typed/cluster-singleton.html) ,它可以保证声明为Singleton的actor在集群内有且只有一个实例存在,同时,在Primary节点挂点后会自动将Singleton actor转移到其它节点。
Akka Distributed Data
对于服务内需要共享数据、计算的情况,可以使用 Akka Distributed Data(之后简称 ADD)。比如:缓存(某种程度上可用于替代类似 Ehcache 和 Caffeine 这样的进程外缓存机制,你只需要更改一个节点的缓存数据,ADD 可以自动在所有节点间同步)、计数(用户积分计算)等。
ADD 使用了CRDTs(Conflict Free Replicated Data Type),所有数据项都通过直接复制或基于gossip协议传播到所有节点或具有特定角色(role)的节点。同时,你还可以对读、写的一致性进行细粒度的控制(ADD 实现了最终一致性,细粒度可用性可以使数据在写入后更及时地在其它节点可见)。
反应式(Reactive)
反应式是近来很火的一个概念,而反应式的理念与微服务非常契合。《反应式宣言》(https://www.reactivemanifesto.org/zh-CN )是一个用户了解反应式概念的很好的开始。Akka提供了强大而丰富的特性以使你可以很方便的基于它开发一个具有反应式特性的系统。
有一本对怎样实现一个反应式系统写得很好的书:《反应式设计模式》,作者为前Akka CTO:Roland Kuhn,值得深读!
Akka Streams
https://doc.akka.io/docs/akka/2.6/stream/
Akka Streams是你用来实现反应式系统的核心,从数据的接收(Akka HTTP),到数据存储(Alpakka JDBC、Alpakka Kafka),可以基于Akka Stream打通整个数据流。
Akka Streams为反应式流开发提供了易于使用的DSL,内建回压支持。Akka Streams是Reactive Streams(Reactive Streams,https://www.reactive-streams.org/ )和JDK 9+ java.util.concurrent.Flow的兼容实现,可与其它实现进行互操作。
Alpakka
https://doc.akka.io/docs/alpakka/current/
Alpakka开源项目为Java和Scala实现了流感知和反应式集成流水线,它建立于Akka Streams之上。Alpakka为常见的数据服务提供了Akka Stream驱动,如:Kafka、Mongodb、Cassandra、JDBC(Slick)……
你可以通过Alpakka Kafka从某个Kafka Topic中消费数据;使用Akka Streams对数据流进行处理;然后使用Alpakka JDBC、Alpakka Mongodb、Alpakka Cassandra的数据库连接器将处理后的数据通过流的方式持久化到PostgreSQL、Mongodb、Cassandra等数据库中。你也可以从持久化数据库中读取数据,通过Akka Streams数据流转换处理后再由Akka HTTP作为服务API发布出去,或由Alpakka Kafka生产数据到Kafka Topic中……
Slick
Slick是针对Scala语言实现的函数式关系映射库(Functional Relational Mapping,FRM),使得对数据库的操作变得容易,就像操作Scala集合库(Collection)一样。同时,Slick也支持直接使用SQL语句(Slick Plain SQL,http://slick.lightbend.com/doc/3.3.1/sql.html )。
一个典型的Slick查询类似:
1 | val q3 = for { |
而直接使用SQL:
1 | // A value to insert into the statement |
在函数式编程中,推荐使用Slick来替代传统的JPA、MyBatis和直接使用JDBC API等作为数据层访问库。Slick具备静态类型(安全)、异步、可组合等特性,同时在某些复杂SQL查询下也支持直接使用SQL语句,但相对于使用JDBC API,Slick Plain SQL也具备静态类型(安全)的特性。
技术降级:Java里好用的工具可继续使用
应用了反应式后,是否以前使用的Java下传统的、非反应式的库、工具都不能使用了呢?答案显然是否定的。比如:MyBatis,Spring的用户大多都使用MyBatis作为持久化层(国内用户),它就是一个典型的非反应式的技术,而且还是一个Scala不友好的技术:可变变量、非编译期检查(使用XML编写SQL语句)……但这里认为,它还是可以使用的,特别是从Spring技术架构迁移到Scala/Akka时。
微服务的一个好外是服务的隔离,我们只需要把可变状态隔离起来即可,隔离的维度可以是服务。我们可以在每个服务内部使用MyBatis,甚至延用Java里定义的DO/Entity类、集合类型(这是Scala对Java友好的地方)。
在这里你能找到在Scala下使用MyBatis的例子(例子使用了MyBatis-plus):https://github.com/ihongka/akka-fusion/blob/master/fusion-mybatis/src/test/scala/fusion/mybatis/FusionMybatisTest.scala 。让我们来看一个测试示例:
1 | test("file insert") { |
TODO
以下内容敬待下一篇:
- 监控
- 通过HTTP Header实现简单的调用链监控
- kamon:自动检测、监视和调试的分布式系统
- 实践
- 全栈 Akka
- 现实:与Spring Cloud一起
- 其它
- Play
- Lagom