ETL(也包括ELT)是数据处理工作里必不可少的步骤,一直以来通常都是以天或小时为单位采用批处理来对大量的数据进行 ETL 操作。随着业务的增长及需求的变化,用户/客户希望能更快的看到各类数据操作的结果,这就催生了实时 ETL 的诉求。
传统上,批量 ETL 会在数据仓库上进行。比如按 天 为单位从一个库同步原始数据到 ODS 层,再通过编写存储过程来对 ODS 层的数据进行加工后将明细数据存储到 DWS 层,然后再对 DWS 层数据作进一步加工形成业务可直接使用的数据。整个处理过程本身非常缓慢,通常需要持续几个小时……
而实时 ETL 通常要求从收到 原始数据 -> 数据清洗、加工 -> 业务可用 在 秒 级时间来完成,且通常为来一条记录既处理一条记录,实现业务数据的实时更新。
本文将将实时 ETL 抽像成 数据接收、数据处理、数据访问 三个部分,并依据此3部分来讨论实时 ETL 的一种建设方案。
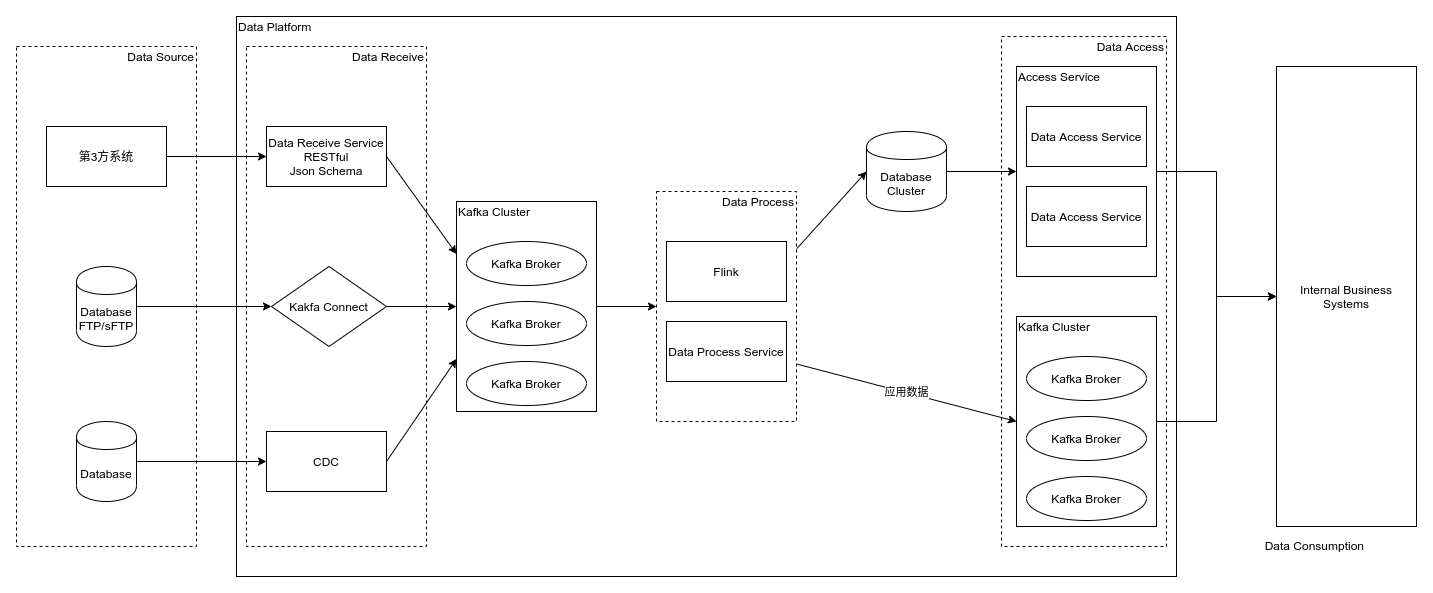
数据接收
数据接收是实时 ETL 的第一步,对于数据接收方式我将期抽像为两类:
- 主动拉取:数据源提供用于数据同步的数据库、FTP/sFTP等,ETL 系统登录上去获取数据接收(常用于传统的批量 ETL)
- 被动接收:提供一个 API(HTTP接口或消息系统),由数据源主动将数据提交上来(实时 ETL 更多使用此种方式)
主动拉取
对于通过数据库同步的方式,传统的批量 ETL 有很多工具可用于数据同步,在此不再做更多的介绍。这里,介绍下实时 ETL 的一种数据拉取方式。
实时 ETL 从数据库拉取数据,可以通过 Kafka Connect JDBC 来拉取表记录并将数据写入 Kafka 主题,这样我们就可以使用各种大数据处理工具(Kafka Streams、Flink、Spark Streaming等)来消费 Kafka 主题的数据并对其进行数据清洗工作。
被动接收
被动接收通常有3种方式
- 提供一个 API(HTTP)接口,数据源调用 API 将数据推送上来
- 提供一个数据步同的消息系统(如:Kafka),数据源向消息系统写入数据
- 通过 CDC 监听业务系统数据库表数据变更
- 通过 Debezium 监听数据库表数据的变更,可实时响应业务系统数据的变化并对其进行加工、分析处理
对于基于 HTTP 的 API 接口,可以考虑使用 JSON Schema 来定义数据校验格式,在数据验证正确后再将数据写入 Kafka。JSON 作为现在最通用的数据格式,可以降低数据对接的技术难度,而因为 JSON 的动态特性,对数据进行格式校验是必不可少的,JSON Schema因其标准化、可扩展性很适合承担此任务。
这里,可以看到各种数据接收方式最终都是把数据写入了 Kafka 消息系统,那我们可以把数据写入其它消息系统或存储系统吗?答案是可以的,但这里建议还是将数据写入 Kafka 进行暂存,因为 Kafka 本身具备数据持久化、高可用/高性能等特性,且与各类数据处理工具都有适配,可以说是现在实事上的大数据处理消息系统标准。当然,也有其它很不错的消息系统(RocketMQ、Pulsar)和存储系统(Pravega)可胜任此任务,但综合技术难度、生态和已有案例,从 Kafka 开始是一个不错的选择。
数据处理
实时数据处理与传统的批量数据处理(ETL)有个显著的不同,通过消息系统与流数据处理系统的结合,可以流水线的形式来对数据进行加工。在数据处理过程中可以做到不 落盘(这里指不像存储的批处理模式那样需要每个步骤处理后需要将数据批量写入各个层里,比如:ODS、DWD、DWS等)。
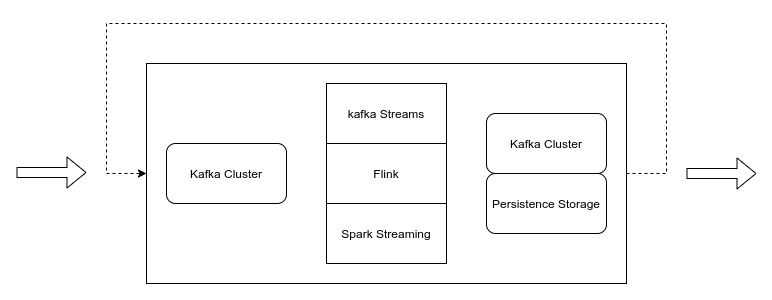
数据处理是一个很灵活的部分,但也有“规则”可循。在这一部分,数据处理抽像为从 Kafka 读取数据,处理完后将数据写入数据存储(通常为 Database)或 Kafka。该一过程可能会有几轮循环,这通常取决于业务复杂程度。
在接收数据我们将数据统一暂存到 Kafka 中,这样在数据处理部分就统一了数据来源。数据处理后的结果存储到数据库中都很容易理解,这是可以直接供业务系统调用的数据(以数据仓库的概念,通常会存储到 APP 层)。
而将处理后的数据再存到 Kafka 是做什么用呢?因为对于实时 ETL,速度为第一要务,处理后的结果需要及时通知业务系统,这就可以通过 Kafka 这样的消息系统来 “推送” 给业务系统(实质上是将结果写入一个 Kafka topic,业务系统监听该 topic)。
实时数据处理,可以运用多种技术来实现,比如:Kafka Streams、Flink/Spark Streaming 等。对于比较简单的实时处理或比较小的技术团队,可以使用 Kafka Streams,相对来说对技术、运维和资源的要求更低。而对于较复杂的实时处理,或团队比较完善,有专门的大数据团队,则可以选择 Flink 或者 Spark Streaming 这样的专而全的实时处理大数据工具。
实时数据处理是一个很大课题,对于怎样进行实时数据处理及技术本身本文不作更多介绍……也许之后我会单独写文章介绍实时数据处理相关知识。
数据访问
实时数据处理,处理后的 结果 数据需要及时推送到业务系统,这可以通过消息系统来实现,Kafka 是一个很好的选择(RocketMQ、Pulsar和RabbitMQ等也可以)。这样从数据接收、数据处理到数据访问既形成了一个完整的 实时 闭环。
在消息推送之外,也需要将结果数据持久化存储下来供业务系统访问。这可以通过两种方式来实现:
- 在流处理中直接将结果写入持久化存储(如数据库)
- 消费推送到 Kafka topic 里的实时结果数据,将其存储到持久化存储
对于存储在持久化存储里的结果数据,可能使用一个统一的 data-access 微服务来像其它业务系统提供服务。通过 RESTful、RPC 等方式将数据接口暴露出去。
总结
本文简单的介绍了实时数据处理可用到的技术与业务分层探索。在大的方面可对实时数据处理分为数据接收、数据处理和数据访问3部分,对每一部分可用到的技术进行了初步的介绍。
实时数据处理还有更多可能等待探索,目的只有一个:天下武功,唯快不破!